The 3% Hallucination Fallacy
For an LLM, a 3% hallucination rate might sound great. But it's a complete fallacy.

Vectara has recently announced its Hallucination Evaluation Model, a FICO-like score for grading LLMs. You can read more in their blog post.
TL;DR – they score many LLMs based on Answer Rate, Accuracy, and Hallucination Rate, which is (1 - Accuracy Rate). A summary of their rankings:

We applaud Vectara for attempting to make head-to-head comparisons across leading LLMs.
However, the above table might lead many to conclude the following:
"3% hallucination? That seems pretty low. I'm OK with 3% hallucination. I'll just use GPT-4."
That 3% is a wild fallacy. Here's why.
To measure "Hallucination Rate", Vectara:
1. Feeds 1,000 documents to each LLM
2. Requests a summary of each document
3. Evaluates the summary of each document for incorrect information
Visually, what's happening is this:
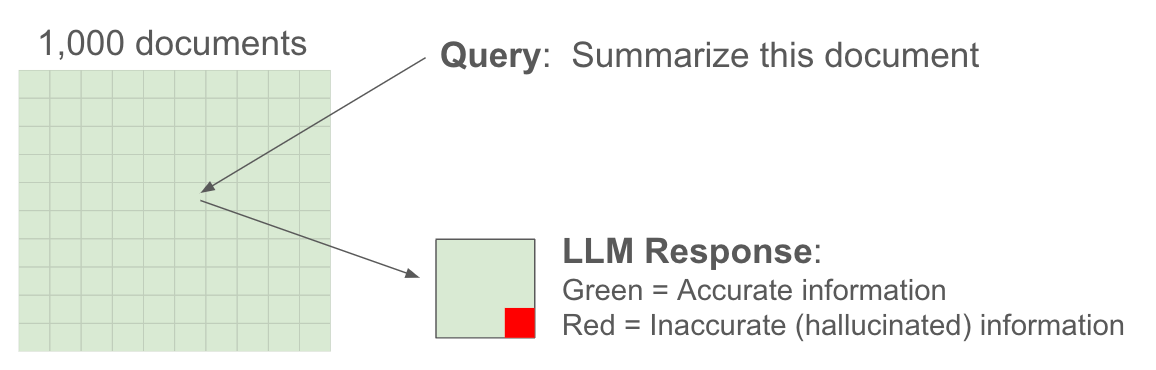
We call the above hallucination metric Grounded Hallucination, i.e., hallucination that happens when a question is grounded in the context that is provided to the LLM.
But LLM hallucination is most common when facts are missing from the provided context, not when facts are present.
LLMs have a bias to provide a response. When facts are missing from the provided context, that's when LLMs go off the rails and hallucinate.
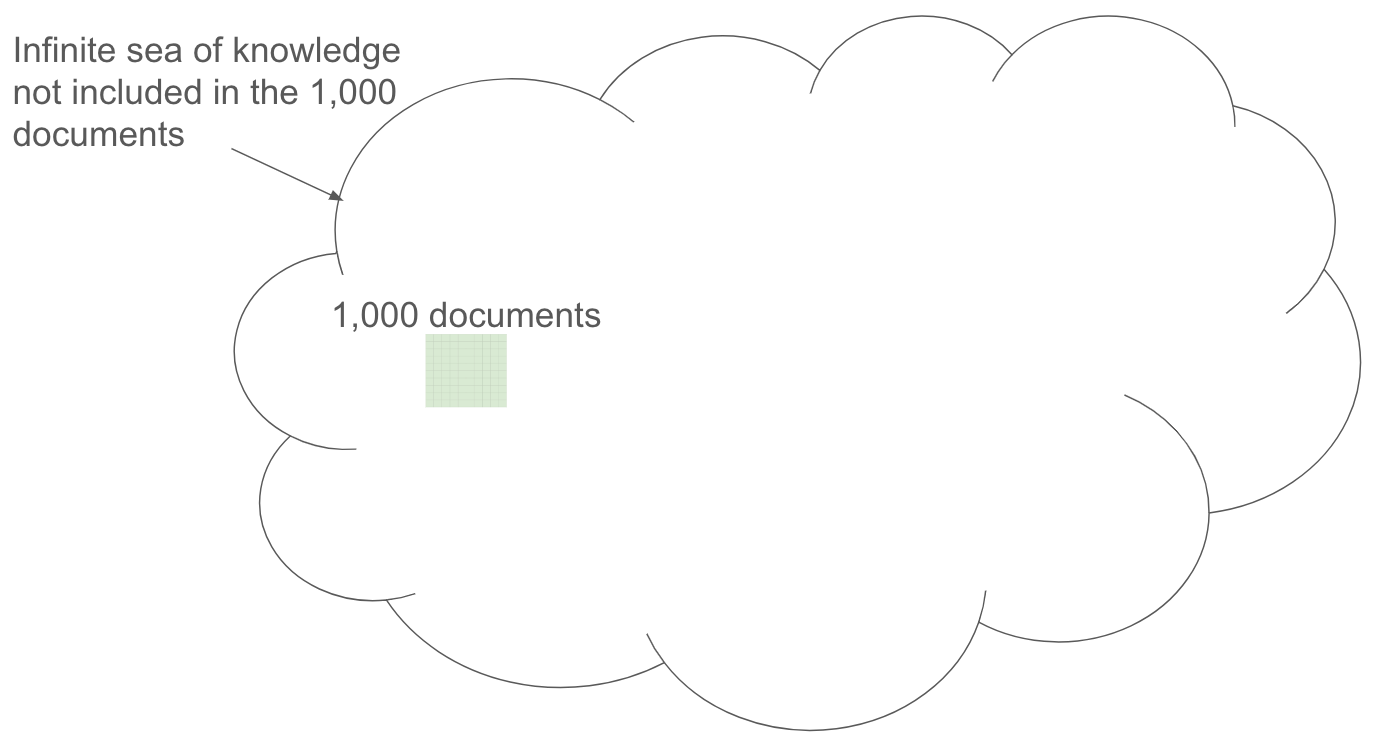
The above methodology misses the vast hallucination forest from the (1,000) trees. The real state of knowledge actually looks like this:
A more holistic process to measure LLM hallucination would look like this:
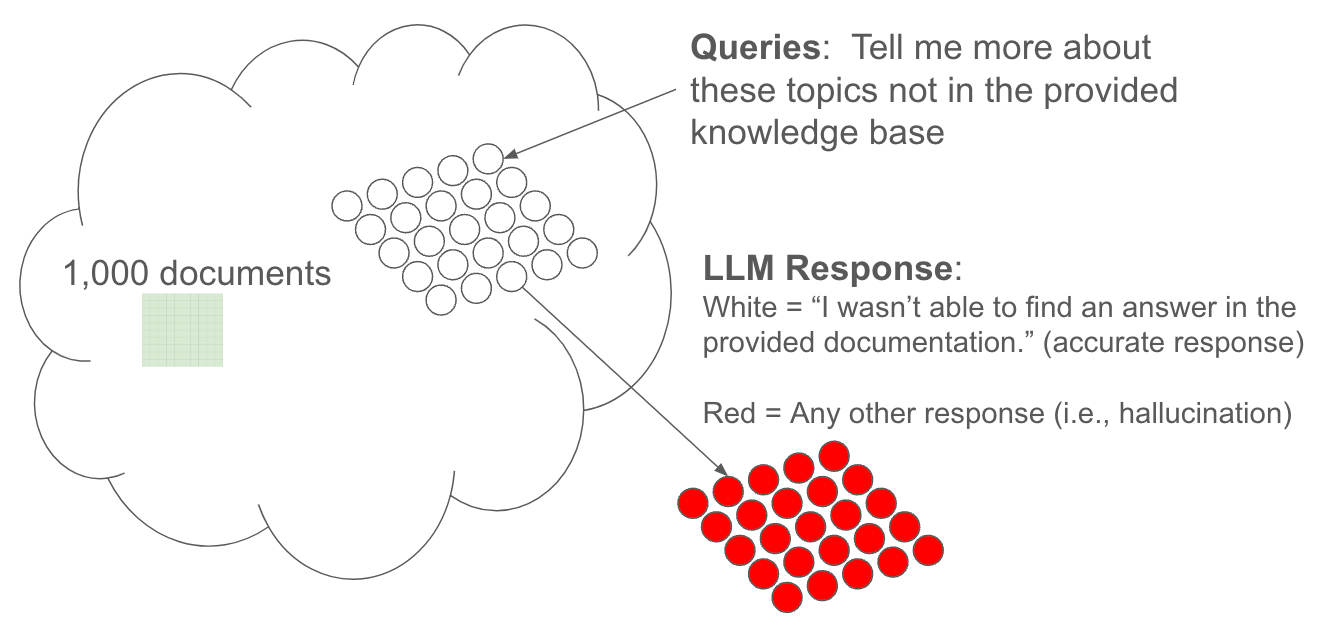
We at Gleen call this Ungrounded Hallucination. Ungrounded Hallucination is when a query is ungrounded (i.e., not contained) in the provided context, and the LLM (or chatbot) provides an equally ungrounded response. That is to say, it hallucinates.
Grounded Hallucination is an inherently narrow measure.
Ungrounded Hallucination is a much more accurate and realistic measure of how frequently and easily an LLM or chatbot will "go off the rails" and make up random stuff.
Enterprises that care about accuracy can't afford to measure only Grounded Hallucination.
When implementing any generative AI solution, enterprises should also understand, care about, and measure Ungrounded Hallucination.
We're Gleen. We build chatbots that don't hallucinate. That includes both Grounded and especially Ungrounded Hallucination.
Request a demo of Gleen AI, or create a free generative AI chatbot with Gleen AI now.


